
قابلیت اطمینان بالای سیستم های ابزار دقیق ایمنی
پرگاران
قابلیت اطمینان بالای سیستم های ابزار دقیق ایمنی :
ایمنی ابزار دقیق را می توان به طور کلی به دو دسته تقسیم کرد: خطرات ایمنی ناشی از ابزارهای ناکارآمد، و سیستم های ابزار ویژه ای که برای کاهش خطرات ایمنی فرآیندهای صنعتی طراحی شده اند. این بخش به دسته اول یعنی سیستم های ابزار دقیق ایمنی
مربوط می شود.
قابلیت اطمینان بالا سیستم های ابزار دقیق ایمنی
 شکن”>
شکن”>
همه روشهای بهبود قابلیت اطمینان، هزینههای اضافی را برای عملیات متحمل میشوند، خواه هزینه سرمایه (هزینه اولیه خرید/نصب) یا هزینههای مداوم (کار یا مواد مصرفی).
انتخاب برای بهبود قابلیت اطمینان سیستم بسیار اقتصادی است. یکی از چالش های انسانی مرتبط با بهبود قابلیت اطمینان، توجیه مداوم این هزینه در طول زمان است. از قضا، هر چه یک برنامه بهبود قابلیت اطمینان موفق تر بوده باشد، اهمیت آن برنامه کمتر است.
مدیر عملیاتی که از مشکلات قابلیت اطمینان رنج می برد، به اندازه مدیر یک مرکز بدون مشکل، نیازی به متقاعد شدن به سود اقتصادی بهبود قابلیت اطمینان ندارد.
علاوه بر این، افرادی که بیشتر از مزایای بهبود قابلیت اطمینان آگاه هستند، معمولاً کسانی هستند که وظایف بهبود قابلیت اطمینان (مانند تعمیر و نگهداری پیشگیرانه) را بر عهده دارند، در حالی که افراد کمتر از مزایای مشابه آگاه هستند. معمولا کسانی هستند که بودجه را مدیریت می کنند.
اگر بین دو اردوگاه اختلاف نظر ایجاد شود، درخواست برای ادامه حمایت مالی از برنامههای بهبود قابلیت اطمینان ممکن است چیزی بیش از نفع شخصی تلقی شود و تنشها را تشدید کند.
روش های مختلفی برای بهبود قابلیت اطمینان سیستم ها وجود دارد. موارد زیر هستند.
طراحی و انتخاب برای قابلیت اطمینان
ممکن است بسیاری از طرح های قابل اجرا برای سیستم های الکترونیکی و مکانیکی به طور یکسان وجود داشته باشد، اما همه آنها از نظر قابلیت اطمینان برابر نیستند. برای مثال، یک عامل اصلی در قابلیت اطمینان ماشین، تعادل است. یک ماشین متعادل با لرزش کمی کار می کند، در حالی که ماشینی که تعادل نامناسب دارد به مرور زمان خود را (و سایر دستگاه هایی که به طور مکانیکی با آن جفت می شوند) تکان می دهد.
قابلیت اطمینان مدارهای الکترونیکی به شدت تحت تأثیر طراحی و همچنین انتخاب جزء است. یک نمونه تاریخی از طراحی مبتنی بر قابلیت اطمینان در سیستم کنترل آنالوگ Foxboro SPEC 200 یافت میشود.
قابلیت اطمینان سیستم کنترل SPEC 200 افسانه ای است، با سابقه ثابت شده از حداقل خرابی ها در طول چندین سال استفاده صنعتی.
طبق ادبیات فنی فاکسبورو، چندین دستورالعمل طراحی به دنبال تجربه کاربردی با ابزارهای میدان الکترونیکی فاکسبورو (به ویژه خطوط مدل “E” و “H”) توسعه یافته است. زیر:
- همه سوئیچ های بحرانی باید بیشتر زمان خود را در حالت بسته بگذرانند
- از استفاده از مقاومتهای ترکیب کربنی خودداری کنید – به جای آن از مقاومتهای سیمی یا فیلمی استفاده کنید
- از استفاده از نیمه هادی های پلاستیکی خودداری کنید – به جای آن از محفظه شیشه ای یا مهر و موم شده استفاده کنید
- تا حد امکان از خازن های الکترولیتی استفاده نکنید – به جای آن از پلی کربنات یا تانتالیوم استفاده کنید
هر یک از این دستورالعمل های طراحی بر اساس به حداقل رساندن خرابی جزء است. اینکه سوئیچ ها بیشتر عمر خود را در حالت بسته سپری کنند به این معنی است که سطوح تماس آنها کمتر در معرض هوا قرار می گیرد و بنابراین در طول زمان کمتر در معرض خوردگی قرار می گیرد (که منجر به یک خطای “باز” می شود.
مقاومتهای سیمپیچ نسبت به طراحیهای شکننده با ترکیب کربن بهتر میتوانند لرزش و آزار فیزیکی را تحمل کنند. نیمه هادی های با روکش شیشه ای و مهر و موم شده هرمتیک بهتر از نیمه هادی های پلاستیکی در از بین بردن رطوبت هستند. خازن های الکترولیتی در مقایسه با انواع دیگر خازن ها مانند پلی کربنات بسیار غیرقابل اعتماد هستند و بنابراین اجتناب از آنها عاقلانه است.
علاوه بر ویژگی های قطعات با کیفیت بالا و شیوه های طراحی عالی، اجزای مورد استفاده در این خطوط از ابزارهای فاکسبورو قبل از مونتاژ برد مدار سوخته شده اند، بنابراین از بسیاری از “اوایل” جلوگیری می شود. خرابیها به دلیل «سوختن» اجزا در حین سرویس واقعی.
نگهداری پیشگیرانه
اصطلاح تعمیر و نگهداری پیشگیرانه به نگهداری (تعمیر یا تعویض) قطعات قبل از خرابی اجتناب ناپذیر آنها در یک سیستم اشاره دارد. به منظور برنامه ریزی هوشمندانه برای تعویض اجزای حیاتی سیستم، آگاهی از طول عمر مفید آن قطعات ضروری است. در “منحنی وان حمام استاندارد، این با زمان فرسودگی یا از بین بردن.
در بسیاری از عملیات صنعتی، تعمیرات پیشگیرانه برنامه ها (اگر اصلاً وجود داشته باشند) بر اساس تاریخچه گذشته طول عمر قطعات و هزینه های عملیاتی متحمل شده به دلیل خرابی آن اجزا هستند. تعمیر و نگهداری پیشگیرانه نشان دهنده یک هزینه اولیه است که در ازای اجتناب از هزینه های بزرگتر در آینده پرداخت می شود.
یک مثال رایج از تعمیر و نگهداری پیشگیرانه و صرفه جویی در هزینه آن، تعویض دوره ای روغن روانکار و فیلترهای روغن برای موتورهای خودرو است. سازندگان خودرو مشخصاتی را برای تعویض روغن و فیلترها بر اساس آزمایش موتورهایشان و فرضیاتی که در رابطه با عادات رانندگی مشتریانشان ارائه میکنند، ارائه میکنند.
برخی از تولیدکنندگان حتی برنامههای تعمیر و نگهداری دوگانه را ارائه میکنند، یکی برای رانندگی “عادی” و دیگری برای رانندگی “سنگین” یا “عملکرد” به منظور در نظر گرفتن سایش سریع.
هرچقدر که تعویض روغن برای یک راننده معمولی بی اهمیت به نظر می رسد، تعمیر و نگهداری منظم سیستم روغن کاری خودرو نه تنها برای عمر طولانی، بلکه برای عملکرد بهینه نیز کاملاً حیاتی است. مطمئناً عواقب عدم انجام این وظیفه تعمیر و نگهداری پیشگیرانه در موتور خودرو پرهزینه خواهد بود.
یک مثال دیگر از تعمیر و نگهداری پیشگیرانه برای افزایش قابلیت اطمینان سیستم، تعویض منظم لامپ ها در آرایه های سیگنال ترافیکی است.
به دلایل نسبتاً واضح، عملکرد مناسب چراغ های راهنمایی برای جریان ترافیک روان و امنیت عمومی بسیار مهم است. تعویض لامپ های چراغ راهنمایی و رانندگی فقط در صورت خرابی، وضعیت رضایت بخشی نخواهد بود، همانطور که با تعویض اکثر لامپ ها معمول است. برای دستیابی به قابلیت اطمینان بالا، این لامپ ها باید قبل از زمان فرسودگی مورد انتظارشان تعویض شوند.
هزینه انجام این تعمیر و نگهداری غیرقابل انکار است، اما هزینه (بزرگتر) ترافیک شلوغ و تصادفات ناشی از سوختن لامپ های راهنمایی و رانندگی نیز همینطور است.
نمونه ای از نگهداری پیشگیرانه در ابزار دقیق صنعتی، نصب و سرویس مکانیزم های خشک کن برای هوای فشرده است که برای تامین انرژی ابزارهای پنوماتیکی و محرک های سوپاپ استفاده می شود.
هوای فشرده یک وسیله بسیار مفید برای انتقال (و ذخیره) انرژی مکانیکی است، اما اگر اجازه داده شود آب در سیستم های توزیع هوا جمع شود، مشکلاتی در ابزارهای پنوماتیک ایجاد می شود. خوردگی، انسداد، و “قفل” هیدرولیک همگی پیامدهای بالقوه هوای “مرطوب” ابزار هستند.
در نتیجه، سیستمهای هوای فشرده ابزاری معمولاً جدا از سیستمهای هوای فشرده (که برای کارکرد ابزارها و محرکهای تجهیزات پنوماتیک همه منظوره استفاده میشوند)، با استفاده از انواع مختلف لوله (پلاستیک، مس، یا فولاد ضد زنگ به جای آهن سیاه یا آهن گالوانیزه) برای جلوگیری از خوردگی و استفاده از مکانیزم های خشک کن هوا در نزدیکی کمپرسور برای جذب و دفع رطوبت.
این خشککنهای هوا معمولاً از یک ماده خشککننده مهرهدار برای جذب بخار آب از هوای فشرده استفاده میکنند و سپس این ماده خشککننده به صورت دورهای از آب باقیماندهاش پاک میشود. با این حال، پس از مدتی کارکرد، ماده خشککننده باید از نظر فیزیکی حذف شود و با خشککننده تازه جایگزین شود.
کاهش رتبه مولفه
برخی از اجزای سیستم کنترل رابطه معکوس بین بار سرویس (چقدر “سخت” جزء استفاده می شود) و عمر سرویس (مدت طول عمر آن) نشان می دهند. در چنین مواردی، یک راه برای افزایش عمر مفید، کاهش نرخ آن جزء است: آن را با بار کمتری نسبت به رتبه طراحی آن کار کنید.
به عنوان مثال، یک درایو موتور با فرکانس متغیر (VFD) برق متناوب را با فرکانس و ولتاژ ثابت می گیرد و آن را به برق متناوب با فرکانس و ولتاژ متغیر تبدیل می کند تا موتور القایی را در سرعت ها و گشتاورهای مختلف به حرکت درآورد.
این دستگاههای الکترونیکی مقداری گرما را عمدتاً به دلیل وضعیتهای روشن (کمی مقاومت) ترانزیستورهای قدرت پخش میکنند. دما یک عامل سایش برای دستگاههای نیمهرسانا است و دماهای بیشتر منجر به کاهش طول عمر میشود.
یک کارکرد VFD در دمای بالا، بنابراین، زودتر از یک VFD که در دمای پایین کار می کند، خراب می شود، زیرا همه عوامل دیگر برابر هستند. یکی از راههای کاهش دمای کارکرد VFD، بزرگ کردن آن برای برنامه است.
اگر موتوری که قرار است رانده شود به ۲ اسب بخار قدرت الکتریکی در بار کامل نیاز دارد و قابلیت اطمینان بیشتری از درایو خواسته می شود، شاید یک VFD 5 اسب بخاری (برنامه ریزی شده با تنظیمات سفر کاهش یافته) مناسب برای موتور کوچکتر) می تواند برای به حرکت درآوردن موتور انتخاب شود.
علاوه بر افزایش عمر سرویس، کاهش رتبه همچنین این قابلیت را دارد که میانگین زمان بین خرابی (MTBF) اجزای حساس به بار را تقویت کند. به یاد داشته باشید که MTBF متقابل نرخ شکست در طول ناحیه پایین “منحنی وان” است که نشان دهنده خرابی های ناشی از دلایل تصادفی است.
این با فرسودگی که افزایش نرخ شکست به دلیل فرسودگی و پیری برگشت ناپذیر است، متفاوت است. دلیل اصلی اینکه یک جزء در نتیجه کاهش رتبه، مقدار MTBF بیشتری از خود نشان میدهد، این است که قطعه بهتر میتواند اضافه بارهای گذرا را جذب کند، که یک علت معمولی خرابی در طول عمر عملیاتی اجزای سیستم است.
مثال یک سنسور فشار را در فرآیندی در نظر بگیرید که موجهای فشار گذرا را نشان میدهد. سنسوری که به گونه ای انتخاب شود که فشار عملیاتی فرآیند معمولی بیشتر محدوده آن را بپوشاند، ظرفیت اضافه فشار کمی خواهد داشت. شاید فقط چند رویداد فشار بیش از حد باعث شود که این سنسور قبل از عمر مفید خود از کار بیفتد.
یک دارای رتبه کم سنسور فشار (با محدوده حسگر فشاری که فشارهای بسیار بیشتری را نسبت به آنچه که معمولاً در این فرآیند با آن مواجه میشود، پوشش میدهد)، در مقایسه، ظرفیت فشار بیشتری برای مقاومت در برابر نوسانات تصادفی خواهد داشت و بنابراین احتمال خرابی تصادفی کمتری را نشان میدهد. /p>
هزینههای مرتبط با کاهش رتبهبندی جزء شامل سرمایهگذاری اولیه (معمولاً بیشتر است، به دلیل ظرفیت بیشتر و ساخت و ساز قویتر در مقایسه با جزء دارای رتبهبندی «معمولاً») و حساسیت کمتر. اگر انتظار میرود که مؤلفه دقت بالا و همچنین قابلیت اطمینان بالایی داشته باشد، فاکتور دوم مهم است.
در مثال سنسور فشار کاهشیافته، دقت احتمالاً کاهش مییابد زیرا محدوده فشار کامل سنسور برای اندازهگیری فشار عادی فرآیند استفاده نمیشود. اگر دستگاه دیجیتال باشد، قطعاً در نتیجه کاهش رتبه دامنه اندازه گیری دستگاه، وضوح تصویر آسیب می بیند.
روش های جایگزین برای بهبود قابلیت اطمینان (از جمله نگهداری پیشگیرانه بیشتر) ممکن است راه حل بهتری نسبت به کاهش رتبه در چنین مواردی باشد.
توجه: بسیاری از اجزاء هیچ رابطه ای بین بار و طول عمر نشان نمی دهند. برای مثال، یک کنترلکننده الکترونیکی PID، در کنترل یک فرآیند خودتنظیمی «آسان» به همان اندازه که یک فرآیند ناپایدار «دشوار» («فرار») را کنترل میکند، دوام خواهد آورد.
ممکن است در مورد سایر مؤلفه های آن حلقه ها چنین چیزی گفته نشود! اگر دریچه کنترل در فرآیند خودتنظیمی به ندرت موقعیت خود را تغییر می دهد، اما شیر کنترل در فرآیند فرار به طور مداوم در تلاش برای تثبیت آن در نقطه تنظیم حرکت می کند، شیر کنترل کمتر فعال به احتمال زیاد از عمر طولانی تری برخوردار خواهد بود.
اجزای اضافی
امتیبیاف هر سیستمی که به اجزای حیاتی خاصی وابسته است ممکن است با کپی کردن آن مؤلفهها به صورت موازی گسترش یابد، به طوری که شکست تنها یکی از آنها کل سیستم را به خطر نیندازد. به این زیادی میگویند.
یک مثال متداول از افزونگی اجزا در سیستم های ابزار دقیق و کنترل، افزونگی ارائه شده توسط سیستمهای کنترل توزیعشده (DCS)، که در آن پردازندهها، کابلهای شبکه و حتی کانالهای ورودی/خروجی (ورودی/خروجی) ممکن است به موارد تکراری آماده به کار آماده باشند. در صورت خرابی مؤلفه اصلی، عملکرد را فرض کنید.
افزونگی تمایل به افزایش MTBF یک سیستم دارد بدون اینکه لزوما عمر سرویس آن را افزایش دهد. برای مثال، یک DCS، مجهز به ماژولهای کنترل ریزپردازنده اضافی در رک خود، MTBF بیشتری نشان میدهد، زیرا یک خطای تصادفی ریزپردازنده با وجود ماژول ریزپردازنده یدکی («استاندبای داغ») پوشش داده میشود.
اما، با توجه به این واقعیت که هر دو ریزپردازنده به طور مداوم انرژی میگیرند، و بنابراین تمایل به سایش با سرعت یکسان دارند، عمر عملیاتی آنها افزایشی نخواهد بود. به عبارت دیگر، دو ریزپردازنده قبل از استفاده دوبرابر کار نخواهند کرد. بیش از یک ریزپردازنده.
توسعه MTBF ناشی از افزونگی تنها در صورتی صادق است که خرابی های تصادفی واقعاً رویدادهای مستقل باشند – یعنی با یک علت مشترک مرتبط نباشند. برای استفاده مجدد از یک رک DCS با ماژولهای کنترل ریزپردازنده اضافی، حساسیت آن قفسه به خطای تصادفی ریزپردازنده تنها در صورتی کاهش مییابد که خطاهای مورد نظر به یکدیگر مرتبط نباشند و بر دو ریزپردازنده تأثیر بگذارند. به طور جداگانه.
ممکن است مکانیسمهای خطای مشترکی وجود داشته باشد که بتواند هر دو ماژول ریزپردازنده را به راحتی غیرفعال کند که میتواند یکی را غیرفعال کند، در این صورت این افزونگی هیچ ارزشی اضافه نمیکند.
نمونههایی از این خطاهای معمولی عبارتند از نوسانات برق (زیرا یک نوسان به اندازه کافی قوی برای از بین بردن یک ماژول به طور همزمان دیگری را از بین میبرد) و عفونت ویروس کامپیوتری (زیرا ویروسی که بتواند به یکی از آنها حمله کند، می تواند به همین راحتی و در همان زمان به دیگری حمله کند.
یک مثال ساده از افزونگی قطعات در یک سیستم ابزار دقیق صنعتی، هدف DC دوگانه منبع تغذیه از طریق یک ماژول دیود تغذیه می شود.
عکس زیر یک نمونه معمولی را نشان می دهد، در این مورد یک جفت Allen-Bradley منابع تغذیه AC-to-DC برای شبکه دیجیتال DeviceNet:

اگر هر یک از دو منبع تغذیه AC-to-DC با ولتاژ خروجی کم از کار بیفتد، منبع تغذیه دیگر می تواند بار را با عبور دادن برق خود از طریق برق حمل کند. ماژول افزونگی دیود:
کلاس

این ماژول افزونگی مقدار MTBF خاص خود را دارد، بنابراین با گنجاندن آن در سیستم یک مؤلفه دیگر اضافه می کنیم که ممکن است خراب شود. با این حال، نرخ MTBF یک شبکه دیود ساده بسیار بیشتر از یک منبع تغذیه AC به DC است، و بنابراین ما با استفاده از این ماژول افزونگی دیود در سطح بالاتری از قابلیت اطمینان نسبت به زمانی که نداشتیم (و فقط یک منبع تغذیه داشتیم) مییابیم. منبع تغذیه).
برای اینکه مؤلفه های اضافی واقعاً MTBF سیستم را افزایش دهند، باید احتمال خرابی های ناشی از علل رایج بررسی شود. به عنوان مثال، اثرات تغذیه منبع تغذیه اضافی AC به DC از همان خط AC را در نظر بگیرید.
منابع تغذیه اضافی قابلیت اطمینان سیستم را در مواجهه با خرابی تصادفی منبع تغذیه افزایش میدهد، اما این افزونگی هیچ کمکی به بهبود قابلیت اطمینان سیستم در صورت از کار افتادن خط برق AC معمولی نمیکند! برای اینکه در این مثال از حداکثر مزیت افزونگی بهره مند شویم، باید هر منبع تغذیه AC به DC را از یک خط متناوب (غیر مرتبط) AC تهیه کنیم.
نمونه دیگری از اضافی در ابزار دقیق صنعتی استفاده از فرستنده های متعدد برای حس کردن یک متغیر فرآیند است، تصور این است که متغیر فرآیند بحرانی حتی در صورت خرابی فرستنده همچنان نظارت خواهد شد. بنابراین، نصب فرستندههای اضافی باید MTBF توانایی سنجش سیستم را افزایش دهد.
در اینجا مجدداً باید به خرابیهای ناشی از علل مشترک بپردازیم تا از مزایای کامل افزونگی بهره ببریم. اگر سه فرستنده سطح مایع برای اندازه گیری نصب شده باشد دقیقاً همان سطح مایع، سیگنال های ترکیبی آنها نشان دهنده افزایش سیستم اندازه گیری MTBF فقط برای خطاهای مستقل است.
یک مکانیسم خرابی مشترک برای هر سه فرستنده، سیستم را به همان اندازه یک فرستنده منفرد در برابر خرابی تصادفی آسیب پذیر می کند. برای دستیابی به MTBF بهینه در آرایههای حسگر اضافی، حسگرها باید از خطاهای رایج مصون باشند.
در این مثال، سه نوع مختلف فرستنده سطح سطح مایع داخل یک کشتی را کنترل می کند، سیگنال های آنها توسط یک عملکرد انتخابگر برنامه ریزی شده در داخل یک DCS پردازش می شود:

در اینجا، فرستنده سطح ۲۳a یک رادار موج هدایت شونده (GWR)، فرستنده سطح ۲۳b یک نوار و شناور است، و فرستنده سطح ۲۳c یک سنسور فشار تفاضلی است.
هر سه سطح سطح مایع را با استفاده از فناوری های مختلف حس می کنند که هر کدام نقاط قوت و ضعف خاص خود را دارند. افزونگی بهتری از اندازهگیری به این ترتیب به دست میآید، زیرا هیچ شرایط فرآیند یا رویداد تصادفی دیگری احتمالاً در هر زمان معین بیش از یکی از فرستندهها را خراب نمیکند.
برای مثال، اگر چگالی مایع فرآیند به طور ناگهانی تغییر کند، بر دقت اندازهگیری فرستنده فشار تفاضلی (LT-23c) تأثیر میگذارد، اما نه فرستنده رادار و نه فرستنده نوار و شناور.
اگر چگالی بخار فرآیند به طور ناگهانی تغییر کند، ممکن است فرستنده رادار (از آنجایی که چگالی بخار معمولاً بر ثابت دی الکتریک تأثیر می گذارد و ثابت دی الکتریک بر سرعت انتشار امواج الکترومغناطیسی تأثیر می گذارد که به نوبه خود بر زمان صرف شده برای پالس رادار تأثیر می گذارد. برای برخورد به سطح مایع و بازگشت)، اما این بر دقت فرستنده شناور تأثیر نمی گذارد و بر دقت فرستنده فشار تفاضلی تأثیر نمی گذارد.
تلاطم سطحی مایع داخل ظرف ممکن است به شدت بر توانایی فرستنده شناور برای تشخیص دقیق سطح مایع تأثیر بگذارد، اما تأثیر کمی بر خوانش فرستنده فشار دیفرانسیل و اندازه گیری فرستنده رادار (با فرض اینکه فرستنده رادار در حالت سکون قرار گرفته باشد. خوب.
اگر تابع انتخابگر اندازه گیری میانه (وسط) یا میانگین بهترین ۲ از ۳ (“۲oo3”) را بگیرد، هیچ یک از این فرآیندهای تصادفی رخ نمی دهد. بر اندازه گیری انتخاب شده سطح مایع در داخل ظرف تأثیر زیادی خواهد گذاشت.
در اینجا افزونگی واقعی به دست می آید، زیرا فرستنده های سه سطح نه تنها احتمال خرابی همزمان (همه) به طور همزمان کمتر از هر فرستنده منفردی است، بلکه به این دلیل که سطح در حال خراب شدن است. به سه روش کاملا متفاوت حس می شود.
یک نیاز اساسی برای اثربخشی افزونگی این است که همه اجزای اضافی باید دقیقاً یک عملکرد فرآیند داشته باشند. در مورد مولفههای DCS اضافی مانند پردازندهها، I/ کارتها و کابلهای شبکه، هر یک از این مؤلفههای زائد نباید چیزی جز بهعنوان «پشتیبان» برای همتایان اصلی خود انجام دهند.
اگر یک گره DCS خاص مجهز به دو پردازنده بود – یکی به عنوان اصلی و دیگری به عنوان ثانویه (پشتیبان) – اما با این حال پردازنده پشتیبان به جزئیات خاص مربوط به آن وظیفه داشت. و نه برای پردازنده اصلی (یا بالعکس)، این دو پردازنده واقعاً برای یکدیگر اضافی نیستند. اگر یکی از پردازندهها از کار بیفتد، دیگری دقیقاً همان عملکرد را انجام نمیدهد و بنابراین عملکرد سیستم (حتی به مقدار کمی) تحت تأثیر خرابی پردازنده قرار میگیرد.
به همین ترتیب، حسگرهای اضافی باید دقیقاً همان عملکرد اندازه گیری فرآیند را انجام دهند تا واقعاً زائد باشند. یک فرآیند مجهز به فرستندههای اندازهگیری سهگانه مانند مثال قبلی که سطح مایع کشتی توسط یک رادار موج هدایتشونده، نوار و شناور و فرستندههای سطح مبتنی بر فشار دیفرانسیل اندازهگیری میشد، از حفاظت افزونگی برخوردار خواهد بود اگر و فقط اگر هر سه فرستنده سطح مایع دقیقاً یکسان را نسبت به همان سطح حس کردند محدوده کالیبره شده.
این اغلب نشان دهنده یک چالش است، در یافتن مکان های مناسب در ظرف فرآیند برای سه ابزار مختلف که بتوانند دقیقاً همان متغیر فرآیند را حس کنند. اغلب، اتصالات لولهای که در ظرف نفوذ میکنند (اغلب نازل نامیده میشوند) برای پذیرش چندین ابزار در نقاط لازم برای اطمینان از ثبات اندازهگیری بین آنها قرار ندارند.
این اغلب زمانی اتفاق میافتد که یک مخزن فرآیند موجود با فرستندههای فرآیند اضافی مجهز شود. ساخت و ساز جدید معمولاً مشکل کمتری دارد، زیرا نازل های لازم و سایر لوازم جانبی ممکن است در موقعیت مناسب خود در مرحله طراحی قرار گیرند.
اگر شرایط جریان سیال در یک مخزن فرآیند بیش از حد متلاطم باشد، سنسورهای متعددی که برای اندازهگیری یک متغیر نصب شدهاند، گاهی تفاوتهای قابل توجهی را گزارش میکنند.
دما چندین برای مثال، فرستندهها که در مجاورت یکدیگر در یک ستون تقطیر قرار دارند، ممکن است تفاوتهای قابلتوجهی دما را گزارش کنند، اگر عناصر حسگر مربوطه (ترموکوپلها، RTDs) با مایع فرآیند یا بخار در نقاطی که الگوهای جریان متفاوت است تماس بگیرند.
چند سنسور سطح مایع، حتی با فناوری یکسان، ممکن است در صورت چرخش یا “قیف” مایع داخل ظرف هنگام ورود و خروج از ظرف، تفاوت در سطح مایع را گزارش کنند.
نه تنها تفاوت های اندازه گیری قابل توجه بین فرستنده های اضافی توانایی آنها را برای عملکرد به عنوان دستگاه های “پشتیبان” در صورت خرابی به خطر می اندازد، چنین تفاوت هایی ممکن است در واقع یک سیستم اضافی را “فریب” دهد. فکر می کنید یک یا چند فرستنده قبلاً از کار افتاده است، در نتیجه باعث می شود اندازه گیری انحراف نادیده گرفته شود.
برای استفاده مجدد از آرایه سنجش سطح سه تکراری به عنوان مثال، فرض کنید فرستنده سطح مبتنی بر رادار به دلیل تأثیرات چرخش مایع در داخل ظرف اگر عملکرد انتخابگر طوری برنامه ریزی شود که چنین اندازه گیری های انحرافی را نادیده بگیرد، سیستم به جای آرایه سه گانه- زائد به یک آرایه تکراری- زائد تنزل می دهد.
به عنوان مثال، در صورت کاهش خطرناک سطح مایع، فقط فرستنده های سطح مبتنی بر رادار و شناور آماده هستند تا این وضعیت خطرناک فرآیند را به سیستم کنترل سیگنال دهند. ، زیرا فرستنده سطح مبتنی بر فشار بسیار بالا است.
تست های اثباتی و خود تشخیصی
یک تکنیک افزایش قابلیت اطمینان مربوط به تعمیر و نگهداری پیشگیرانه ابزارها و عملکردهای حیاتی، اما عموماً به گرانی تعویض قطعه نیست، آزمایش دوره ای عملکرد جزء و سیستم است.
عادی “تست اثبات” اجزای حیاتی MTBF یک سیستم را به دو دلیل مختلف افزایش میدهد:
- تشخیص زودهنگام مشکلات در حال توسعه
- «تمرین» منظم اجزاء
اول، آزمایش اثبات ممکن است نقاط ضعف در حال توسعه در اجزا را نشان دهد، که نشان دهنده نیاز به جایگزینی در آینده نزدیک است. مشابه این، مراجعه به پزشک برای انجام یک معاینه جامع است – اگر این کار به طور منظم انجام شود، شرایط بالقوه کشنده ممکن است زود تشخیص داده شود و از بحران جلوگیری شود.
دومین روشی که تست اثبات قابلیت اطمینان سیستم را افزایش می دهد، درک اثرات مفید عملکرد منظم است. عملکرد بسیاری از اجزاء و انواع سیستمها پس از دورههای طولانی عدم فعالیت کاهش مییابد.
این تمایل بیشتر در سیستم های مکانیکی رایج است، اما برای برخی از اجزاء و سیستم های الکتریکی نیز صادق است. به عنوان مثال، شیرهای برقی ممکن است در جای خود «گیر کنند» اگر برای مدت طولانی چرخه نشوند.
برینگ ها ممکن است خورده شوند و در صورت بی حرکت باقی بمانند. هر دو باتری سلول اولیه و ثانویه به دلیل تمایل به خراب شدن پس از دوره های طولانی عدم استفاده شناخته شده اند.
دوچرخه منظم چنین اجزایی در واقع قابلیت اطمینان آنها را افزایش می دهد و احتمال خرابی مربوط به “رکود” را خیلی قبل از سپری شدن عمر مفید رتبه بندی شده کاهش می دهد.
یکی از بخشهای مهم هر برنامه آزمایش اثباتی این است که اطمینان حاصل شود که در صورتی که تست اثبات یک مؤلفه ناموفق را نشان دهد، یک انبار آماده از قطعات یدکی در دسترس است.
اگر کامپوننت شکست خورده را نتوان فوراً تعمیر یا تعویض کرد، آزمایش اثبات ارزش کمی دارد، بنابراین این اجزای انبار شده باید با پارامترهای دقیق لازم برای پیکربندی (یا به راحتی قابل تنظیم باشند) نصب فوری.
یک گرایش رایج در تجارت، تمرکز توجه بر مهندسی و نصب سیستمهای فرآیند و کنترل، اما از سرمایهگذاری در مواد پشتیبانی و زیرساخت برای حفظ آن سیستمها در شرایط عالی غفلت میکنند. سیستم های با قابلیت اطمینان بالا نیازهای خاصی دارند و این یکی از آنهاست.
روشهای آزمایش اثبات
مستقیم ترین روش آزمایش یک سیستم حیاتی این است که آن را تا محدوده محدوده خود تحریک کنید و واکنش آن را مشاهده کنید. برای یک فرستنده فرآیند، این نوع آزمایش معمولاً به شکل یک بررسی کالیبراسیون کامل است.
برای یک کنترلکننده، آزمایش اثبات شامل هدایت تمام سیگنالهای ورودی در محدودههای مربوطه در همه ترکیبها برای بررسی پاسخ (های) خروجی مناسب است. برای عنصر کنترل نهایی (مانند یک شیر کنترل)، این امر مستلزم نوازش کامل عنصر، همراه با آزمایشهای نشت فیزیکی (یا ارزیابیهای دیگر) است تا اطمینان حاصل شود که عنصر اثر مورد نظر را بر فرآیند دارد.
یک چالش آشکار برای آزمایش اثبات این است که چگونه می توان چنین آزمون های جامعی را بدون ایجاد اختلال در روند عملکرد آن انجام داد. تست اثباتی خارج از سرویس ابزار یک موضوع ساده است، اما تست اثبات ابزار نصب شده در یک سیستم کاری کاملاً چیز دیگری است.
چگونه میتوان فرستندهها، کنترلکنندهها و عناصر کنترل نهایی را در کل محدوده عملیاتی خود بدون ایجاد مزاحمت (بهترین حالت) یا توقف (بدترین حالت) فرآیند دستکاری کرد؟ حتی اگر ممکن است همه آزمایشها در فواصل زمانی مورد نیاز در طول دورههای خاموشی انجام شوند، آزمایشها به اندازهای که فرآیند در فشارها و دماهای معمولی عمل میکند واقعی نیستند. مؤلفههای آزمایش اثبات در شرایط واقعی «اجرای» واقعیترین راه برای ارزیابی آمادگی آنها است.
یکی از راههای اثبات آزمایش ابزارهای حیاتی با کمترین تأثیر بر ادامه عملکرد یک فرآیند، انجام آزمایشها بر روی برخی مؤلفهها است، نه همه آنها.
به عنوان مثال، گرفتن یک فرستنده در یک فرآیند عملیاتی از سرویس خارج می شود تا پاسخ آن به محرک ها را بررسی کند: به سادگی کنترل کننده را در حالت دستی قرار دهید و اجازه دهید یک اپراتور انسانی فرآیند را کنترل کند. به صورت دستی در حالی که یک تکنسین ابزار فرستنده را آزمایش می کند.
در حالی که مسلماً این استراتژی جامع نیست، حداقل آزمایش اثبات برخی از ابزارها بهتر از آزمایش اثبات هیچ یک از آنها است.
یکی دیگر از روشهای آزمایش اثبات این است که “تست تا خاموش کردن:” زمانی را انتخاب کنید که پرسنل عملیات برنامه ریزی کنند تا فرآیند را به هر حال خاموش کنند، سپس از آن زمان به عنوان فرصتی برای اثبات استفاده کنید. – تست یک یا چند جزء حیاتی لازم برای اجرای سیستم. این روش از بیشترین درجه واقع گرایی برخوردار است، در حالی که از ناراحتی و هزینه وقفه غیرضروری فرآیند جلوگیری می کند.
روش دیگری برای انجام آزمایشهای اثبات بر روی ابزار دقیق این است که سرعت محرکهای آزمایشی را تسریع کنیم تا عناصر کنترل نهایی به اندازه کافی واکنش نشان ندهند که عملاً فرآیند را مختل کند. اما به اندازه کافی پاسخگویی همه (یا اکثر) اجزای مورد نظر را ارزیابی می کند.
صنایع انرژی هسته ای گاهی اوقات از این تکنیک تست اثبات استفاده می کند، با اعمال سیگنال های پالس با سرعت بالا به سنسورهای خاموش شدن ایمنی به منظور آزمایش عملکرد صحیح منطق خاموش شدن، بدون اینکه عملاً خاموش شود. راکتور خاموش است.
آزمایش شامل تزریق سیگنالهای پالس کوتاه مدت در سطح حسگر، سپس نظارت بر خروجی منطق خاموشسازی برای اطمینان از ارسال سیگنالهای پالس بعدی به دستگاه(های) خاموشکننده است. .
صنایع مختلف شیمیایی و نفت از روش تست اثبات مشابهی برای دریچههای ایمنی به نام تست ضربهای جزئی، که به موجب آن سوپاپ تنها بخشی از مسیر حرکت خود را تحت فشار قرار میدهد: به اندازهای است که اطمینان حاصل شود که شیر قادر به حرکت کافی بدون بسته شدن (یا باز کردن، بسته به آن) است. در عملکرد شیر) به اندازه ای است که در واقع فرآیند را مختل کند.
سیستمهای اضافی مزایا و چالشهای منحصربهفردی را برای تست اثبات اجزا ارائه میدهند. مزیت یک سیستم اضافی در این زمینه این است که هر یک از اجزای اضافی ممکن است برای آزمایش بدون اقدام خاصی توسط پرسنل عملیات از سرویس حذف شود.
برخلاف یک سیستم “simplex” که در آن حذف یک ابزار به یک اپراتور انسانی نیاز دارد که کنترل را در طول مدت آزمایش به صورت دستی در دست بگیرد، اجزای “پشتیبان” یک سیستم اضافی باید این کار را به صورت خودکار انجام دهید، از نظر تئوری انجام آزمون را بسیار آسان تر می کند.
اما، چالش انجام این کار این واقعیت است که بخشی از سیستم که مسئول اطمینان از انتقال یکپارچه در صورت خرابی است، در واقع یک جزء مستعد خرابی است.
تنها راه برای آزمایش این مؤلفه این است که در واقع یک (یا بیشتر، در پیکربندی های بسیار زائد) از مؤلفه های اضافی را غیرفعال کنید تا ببینید آیا مؤلفه(های) باقیمانده کار می کنند یا خیر. نقش های اضافی آنها.
بنابراین، اگر همه اجزای سیستم خوب باشند، آزمایش اثباتی یک سیستم اضافی خطری ندارد، اما در صورت بروز یک خطای شناسایی نشده، خطر اختلال در روند وجود دارد.
اجازه دهید بار دیگر به سیستم فرستنده سطح سه گانه خود بازگردیم تا این مفاهیم را بررسی کنیم. فرض کنید میخواهیم یک آزمایش اثباتی فرستنده سطح مبتنی بر فشار انجام دهیم.
به عنوان یکی از سه فرستنده که سطح مایع را در این کشتی اندازه گیری می کنند، باید بتوانیم آن را بدون هیچ آمادگی (به غیر از اطلاع دادن به پرسنل عملیات از آزمایش و آزمایش) از سرویس خارج کنیم. پیامدهای بالقوه) زیرا عملکرد انتخابگر باید به طور خودکار فرستنده غیرفعال را از حالت انتخاب خارج کند و به اندازه گیری فرآیند از طریق دو فرستنده باقی مانده ادامه دهد.
اگر آزمایش اثبات موفقیت آمیز باشد، نه تنها ثابت می کند که فرستنده کار می کند، بلکه همچنین نشان می دهد که عملکرد انتخابگر به اندازه کافی وظیفه خود را در “پشتیبان گیری” از فرستنده آزمایش شده انجام داده است. حذف شد.
اما، اگر هنگام غیرفعال کردن فرستنده یک سطحی برای آزمایش اثبات، عملکرد انتخابگر ناموفق بود، سیگنال سطح فرآیند انتخابی میتواند به جای جابجایی به مقدار معیوب ثبت کند. دو سیگنال فرستنده باقی مانده.
این ممکن است روند را مختل کند، به خصوص اگر سیگنال سطح انتخاب شده به یک حلقه کنترل یا یک سیستم خاموش شدن خودکار برود. البته میتوانیم با قرار دادن سیستم کنترل در حالت “دستی” در حالی که ما آن یک فرستنده را از سرویس حذف می کنیم، فقط در صورتی که افزونگی مطابق طراحی عمل نکند.
اما با انجام این کار، افزونگی سیستم به طور کامل آزمایش نمی شود، زیرا با قرار دادن سیستم در حالت دستی قبل از آزمایش، اجازه نمی دهیم منطق اضافی به طور کامل همانطور که می خواهد عمل کند. انتظار می رود در صورت خرابی واقعی ابزار.
آزمایش اثبات منظم یک فعالیت ضروری برای دستیابی به قابلیت اطمینان بهینه برای هر سیستم حیاتی است. با این حال، در تمام آزمایشهای اثباتکننده، ما با یک انتخاب روبرو هستیم: یا قطعات را تا حد کامل، در حالتهای عملیاتی معمولی آزمایش کنیم، و خطر (یا شاید تضمین) اختلال در فرآیند را داشته باشیم. یا آزمایشی را انجام دهید که از جامعیت کمتری برخوردار است، اما با خطر کمتر (یا بدون) اختلال در فرآیند.
در اکثریت قریب به اتفاق موارد، گزینه دوم صرفاً به دلیل هزینه های مرتبط با اختلال در فرآیند انتخاب می شود. چالش ما بهعنوان متخصصان ابزار دقیق، تدوین آزمونهای اثبات است که تا حد امکان جامع باشند و در عین حال کمترین اختلال را در روندی که در تلاش برای تنظیم آن هستیم، داشته باشند.
خود تشخیصی ابزار
یکی از مزایای بزرگ فناوری الکترونیک دیجیتال در ابزار دقیق صنعتی، گنجاندن توانایی خود تشخیصی در ابزارهای میدانی است.
یک ابزار “هوشمند” حاوی ریزپردازنده خود ممکن است برای شناسایی شرایط خاصی که نشان دهنده خرابی سنسور یا مشکلات دیگر است برنامه ریزی شود، سپس به سیستم کنترل سیگنال دهد که مشکلی وجود دارد.
اگرچه خود تشخیصی هرگز نمی تواند کاملاً مؤثر باشد زیرا به ناچار مواردی از خطاهای کشف نشده و حتی موارد مثبت کاذب (اعلام خطا در جایی که وجود ندارد) وجود خواهد داشت، وضعیت فعلی امور به طور قابل توجهی بهتر از روزهای فناوری آنالوگ صرف است که در آن ابزارها قابلیت تشخیص خود ناچیز یا نداشتند.
ابزارهای میدان دیجیتال این توانایی را دارند که پیامهای خطای خود تشخیصی را به سیستم میزبان خود از طریق همان شبکههای “فیلدباس” که برای برقراری ارتباط دادههای فرآیند معمولی استفاده میکنند، ارسال کنند.
FOUNDATION Fieldbus ابزارها به ویژه قابلیت گزارش خطای گسترده ای دارند، از جمله یک متغیر “وضعیت” مرتبط با هر سیگنال فرآیندی که در تمام بلوک های تابع مسئول کنترل فرآیند منتشر می شود. هنگامی که ابزارها توانایی ارتباط دیجیتال کامل را داشته باشند، خطاهای شناسایی شده به طور موثر در سراسر زنجیره اطلاعات در سیستم ارتباط برقرار می کنند.
ابزارهای “هوشمند” با توانایی خود تشخیصی، اما محدود به سیگنال دهی آنالوگ (مثلاً ۴-۲۰ میلی آمپر DC) ممکن است اطلاعات خطا را نیز منتقل کند، نه به آسانی یا جامع بودن یک ابزار کاملا دیجیتال.
NAMUR برای سیگنال دهی ۴-۲۰ میلی آمپر (NE-43) ابزاری برای انجام این کار فراهم می کند:

تفسیر مناسب این محدودههای جریان خاص، البته نیاز به گیرندهای دارد که قادر به اندازهگیری دقیق جریان خارج از محدوده استاندارد ۴-۲۰ میلی آمپر باشد. بسیاری از سیستم های کنترلی با قابلیت ورودی آنالوگ به گونه ای برنامه ریزی شده اند که سطوح فعلی نشان دهنده خطای NAMUR را تشخیص دهند.
یک چالش برای هر سیستم خود تشخیصی این است که چگونه خطاهای “مغز” خود واحد را بررسی کند: ریزپردازنده. اگر خرابی در ریزپردازنده یک ابزار “هوشمند” رخ دهد – همان مؤلفه ای که مسئول انجام عملکردهای منطقی مربوط به آزمایش خود تشخیصی است – چگونه می تواند یک نقص در منطق را تشخیص دهد؟ این سوال تا حدودی فلسفی است، معادل تعیین اینکه آیا یک متخصص مغز و اعصاب قادر به تشخیص مشکلات عصبی خود است یا خیر.
یک روش ساده برای تشخیص خطاهای فاحش در یک سیستم ریزپردازنده به عنوان تایمر سگ نگهبان شناخته می شود. این اصل به این صورت عمل می کند: ریزپردازنده طوری برنامه ریزی شده است که یک سیگنال پالس فرکانس پایین را به طور مداوم خروجی دهد، با یک مدار خارجی که سیگنال پالس را برای هرگونه وقفه یا انجماد “نظارت” می کند. اگر ریزپردازنده به نحو قابل توجهی از کار بیفتد، سیگنال پالس یا پالسها را رد میکند یا در حالت بالا یا پایین «یخ میزند»، بنابراین نشاندهنده خرابی ریزپردازنده در مدار «سگ نگهبان» است.
می توان با استفاده از یک جفت زمان بندی حالت جامد یک مدار تایمر نگهبانی ساخت رله متصل به کانال خروجی پالس دستگاه ریزپردازنده:

هر دو تایمر تأخیر و تأخیر، سیگنال پالس یکسانی را از ریزپردازنده دریافت میکنند، ورودیهای آنها مستقیماً موازی با خروجی پالس ریزپردازنده متصل میشوند. تایمر تأخیر خاموش بلافاصله با دریافت سیگنال «بالا» فعال میشود، و زمانی شروع می شود که سیگنال پالس “کم” می شود.
تایمر تاخیری در طول یک سیگنال “بالا” شروع به زمانبندی میکند، اما هر زمان که سیگنال پالس “کم” شد، فوراً غیرفعال میشود. تا زمانی که تنظیمات زمان برای رلههای تایمر تاخیری و خاموشی به ترتیب بیشتر از زمانهای “بالا” و “پایین” سیگنال پالس نگهبان باشد، تا زمانی که سیگنال پالس ادامه دارد، هیچ یک از تماسهای رله باز نمیشوند. الگوی منظم آن.
هنگامی که ریزپردازنده به طور معمول رفتار می کند و سیگنال پالس نگهبان معمولی را صادر می کند، تماس تایمر تاخیر خاموش در حالت بسته باقی می ماند زیرا با هر سیگنال “بالا” همچنان انرژی می گیرد. و هرگز زمان کافی برای خروج در طول هر سیگنال “کم” را ندارد.
به همین ترتیب، تماس تایمر تاخیری در حالت عادی بسته خود باقی می ماند زیرا هرگز زمان کافی برای دریافت در طول هر سیگنال “بالا” قبل از غیرفعال شدن با هر “کم” ندارد. ” علامت. وقتی همه چیز خوب باشد، هر دو کنتاکت رله زمانبندی در حالت بسته خواهند بود.
اما، اگر سیگنال خروجی پالس ریزپردازنده در حالت “کم” منجمد شود (یا از یک پالس “بالا” رد شود)، تایمر تاخیر خاموش میشود. باز کردن تماس آن و علامت دادن یک خطا.
برعکس، اگر سیگنال پالس ریزپردازنده در حالت “بالا” منجمد شود (یا از یک پالس “کم” رد شود)، تایمر تاخیر فعال می شود و تماس آن باز می شود. و علامت دادن خطا هر یک از رلههای زمانبندی که تماس خود را باز میکنند، سیگنالهای قطع یا توقف سیگنال پالس نگهبان را نشان میدهند که نشاندهنده یک خطای جدی ریزپردازنده است.
مقالاتی که ممکن است دوست داشته باشید:
نمودار شماتیک
فرآیند اینترلاک و سفر
سوالات شیر برقی
شماتیک موقعیت یاب شیر
PLC مستندات
در صورت هرگونه سوال و نظر با مجموعه پرگاران تماس حاصل فرمایید.
جهت کسب اطلاعات بیشتر اینجا کلیک کنید.
مطالب مرتبط
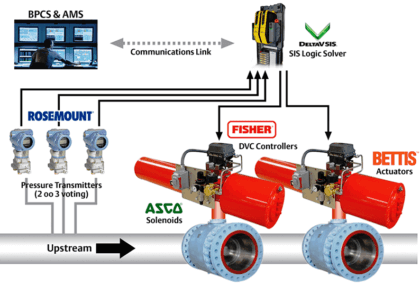
سیستم خاموش کردن اضطراری چیست؟
خاموسیستم خاموش کردن اضطراری چگونه عمل میکند ؟ بیایید به بررسی این موضوع بپردازیم
نحوه عملکرد سیستم خاموش ...
پرگاران

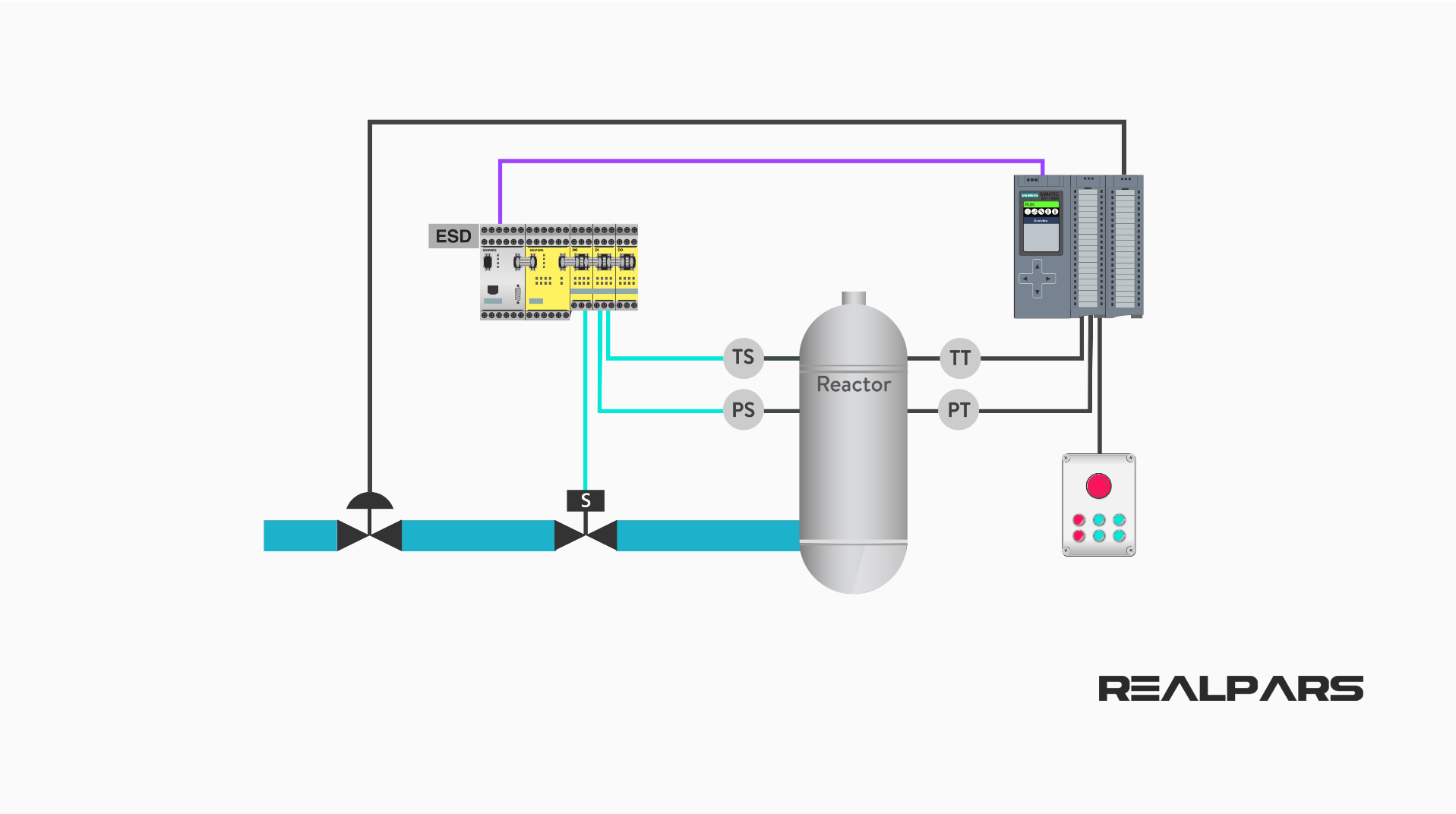
سیستم کنترل ایمنی چیست؟
سیستم کنترل ایمنی:
یک سیستم کنترل ایمنی یا دستگاه در صورتی مرتبط با ایمنی تلقی می شود که ...
پرگاران
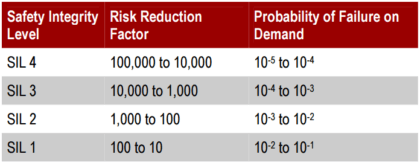
اهمیت سطح یکپارچگی ایمنی
اهمیت سطح یکپارچگی ایمنی چیست؟
اهمیت جهانی SIL (سطح یکپارچگی ایمنی) در صنایع نفت/گاز، پتروشیمی و سایر ...